Demystifying AI for the rest of us
A practical guide to understanding how LLMs work, their limitations, and how to use them effectively - no degree required.
"A guide to taming the world's most sophisticated autocomplete"
Everyone's using AI these days, whether that's ChatGPT, Claude, Gemini, or DeepSeek, and you've probably tried at least one of them. The real question is whether you're actually getting much out of it, and whether AI is genuinely intelligent or whether something else is going on under the hood. You don't need to know how to code, and you don't need a math degree to understand this; you just need to know how the thing works.
Typing a prompt and blindly hoping for a good response will only get you so far. To get more out of these tools, you need to understand the mechanism behind them. In this post, I'll break down how LLMs are made, how they function, and why they behave the way they do, without the complex technobabble.
From there, I'll cover practical ways to work around the limitations of modern AI. By the end, you'll understand why your 20-message conversation started giving worse answers, why the AI agrees with whatever you imply, and why it nails creative writing but sometimes fumbles basic arithmetic. These quirks will stop being frustrating mysteries and start being predictable behaviours that you can work around. Consequently, these lessons should make you more effective with AI today, and help you keep up as it evolves.
How did we get here? The road to modern LLMs
The desire for artificial intelligence is something humanity has sought throughout history. AI has often been depicted in historical literature as independent automatons, golems, and robots, forging intelligence out of inanimate matter. However, the actual scientific approach to AI only really started in the 1950s.
To understand why today's AI feels so different from the chatbots of the past, it helps to look at the bottlenecks that were overcome along the way. Early attempts at AI involved rigid, hand-coded rules (1960s to 1990s), which subsequently shifted towards statistical models (1990s to 2010s) that simply guessed the next word based on probability. Then came neural networks (2010 to 2017), which learned to find patterns in text but also had major limitations: training was painfully slow, and the models would lose track of information in longer inputs (think of forgetting the beginning of a story by the time it reached the end). The transformer architecture subsequently solved both problems, since its attention system could track contextual connections across entire passages, and it could be trained much faster using modern GPU computing power.
Under the hood, all of this works because text gets converted into numbers. Words and word-pieces become numerical representations (known as vector embeddings), and training means adjusting millions to billions of numbers until the model gets good at predicting what comes next. Those numbers, called parameters or weights, are what define how the model behaves. If you're interested in the technical details, check out 3Blue1Brown's excellent playlist on neural networks and transformers, otherwise keep on reading.
What's striking is that beneath all of this technological progress and complexity, the core mechanism has stayed the same since the statistical model era: predicting what text comes next.
It's autocomplete all the way down
The part that surprises most people is that modern LLMs, including ChatGPT, Claude, Gemini, and DeepSeek, are still just predicting the next piece of text. That's the entire mechanism: given everything that came before, what's the most probable thing to say next?
Before ChatGPT
Early models like GPT-2 (2019) and GPT-3 (2020) couldn't have conversations. If you asked "What is the capital of France?", GPT-2 might respond with "And what is the capital of Germany? These are questions that...". It wasn't answering, it was completing text as if your question was the start of an essay.
GPT-3 was more capable but required tricks. If you wanted it to translate English to French, you couldn't just ask. You had to show the pattern first:
English: cheese => French: fromage
English: thank you => French: merci
English: I would like coffee => French:GPT-3 would then complete with je voudrais du café. You had to prime the conversation with examples so that the model could pattern-match what you wanted, which gave birth to early "prompt engineering". It worked, but it felt more like programming than conversation.
ChatGPT changed everything
In 2022, ChatGPT took the same underlying technology and added one crucial thing: fine-tuning on curated conversation examples. These weren't scraped from the internet; they were written by skilled human labellers following specific tone and content guidelines set by each company. The exact training data numbers aren't public, but we're talking on the order of tens of thousands of examples. The surprising insight here is just how little data it takes to teach a massive model new behaviour.
In a very real sense, when ChatGPT responds, it's approximating how those labellers would respond. The helpful-but-careful tone, the structured explanations, and the tendency to caveat aren't signs of an emergent AI personality, but rather the model predicting what those humans would have written. Today, much of this data is LLM-generated, but it's still curated and filtered by humans to maintain quality.
Even after all of this, the core mechanism is still predicting what comes next. However, the training has now taught the model that what comes next in a conversation is an answer.

Reasoning models: autocomplete that shows its work
Starting in 2024, a new type of model emerged: reasoning models (e.g., OpenAI o1, DeepSeek R1). These models are trained to break down problems step-by-step before answering, and they're much better at math, coding, and logic puzzles, although still far from perfect.
However, this isn't a fundamentally novel approach. It's a progressive improvement to training data, since instead of simple question → answer pairs, the training examples were expanded to include intermediate steps via "showing your work". Effectively, this gives the model more surface area to learn patterns on.
The result is models that generate longer reasoning chains before arriving at an answer, but it's still predicting based on patterns. They can show their work beautifully and still arrive at the wrong conclusion, and there's also a trade-off in increased time and cost. For simple questions, reasoning models are overkill, but for harder problems they can certainly help.
A statistical soul
Let's discuss what "predicting the next piece of text" actually means.
Digesting language, one token at a time
LLMs don't read letters or words; they read tokens, which are chunks of text that the model learned to recognise. A token might be:
- A whole word:
cat - Part of a word:
inginrunning(common examples being compound words and conjugation affixes) - Punctuation:
. - A space:
Common words become single tokens, whereas rare or long words get split. For example, Extraordinary might become extra + ordinary, and Antidisestablishmentarianism becomes many pieces.

This matters practically, since longer conversations cost more, and modern LLMs have a limit on how much they can "see" at once. That limit is measured in tokens (roughly 1,000 tokens ≈ 750 English words).
What are the chances?
When generating text, the model doesn't simply pick "the best" next word. Instead, it calculates a probability distribution over its entire vocabulary.
For the sentence The cat sat on the ____, the probability of all possible options is computed for the next token:
| Word | Probability |
|---|---|
mat | 35% |
floor | 25% |
couch | 15% |
table | 10% |
| ... thousands of other less likely options | 15% (combined) |
The model then samples from this distribution, essentially rolling the dice weighted by these probabilities.
Turning up the heat
Temperature controls how the model samples from these probabilities.
- Temperature = 0: Always pick the highest probability token. This is almost deterministic, since the same input usually produces very similar output. Good for factual questions where consistency matters.
- Temperature ~ 0.3-0.5: Mostly predictable with slight variation. The model occasionally picks a less-likely token but stays conservative. Good for coding, technical writing, and structured tasks where you want reliability with a touch of flexibility.
- Temperature ~ 0.7: A popular default, balanced between coherence and creativity. Good for general conversation.
- Temperature = 1: Sample fully proportional to the probabilities. The output is more creative, more surprising, and occasionally odd. Good for brainstorming and creative writing.
This is why you can ask the same question twice and get different answers; it's not a bug, but rather by design. Randomness is built into how the system chooses words.
Patterns, not principles
Where it gets particularly interesting is in the source of the model's learning: LLMs learned from text that describes experiences, not from experiences themselves. They've read millions of descriptions of what good writing looks like, what helpful answers sound like, and how conversations flow. However, they've never felt the pain of touching a hot stove or the awkwardness of saying the wrong thing.
Newer multimodal models (ones that process text, images, audio, and video together, like when you upload a screenshot to an AI chat) are a significant improvement on this front. The word "cat" gets connected to visual features and actual sounds rather than just text, although this is still fundamentally pattern matching on those data. Consequently, today's models understand context that would've stumped earlier ones. Nevertheless, watching and listening to recordings of the world isn't the same as living in it; LLMs observe the artifacts of experience, not experience itself.
This matters practically, since LLMs excel at tasks that look like what they've seen before, but they struggle with novel situations. Ask one to add two very large numbers and it might botch it, because it learned what arithmetic looks like, not how to actually compute.
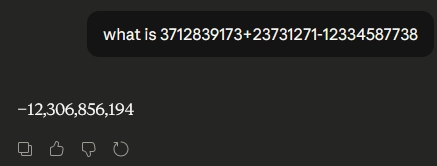
-8,598,017,294.Modern LLMs try to work around this limitation with tool calling. The model is trained to recognise when it should hand off work to an external system, like a calculator, search engine, or code interpreter. When you ask a math question, the model recognises this pattern, reaches out to an actual calculator, waits for the answer, and then presents it to you. The LLM handles the conversation while the tool handles the computation. Effectively, it's pattern matching on when to ask for external help, not on how to solve the problem itself.
However, tools only help when the model knows to use them. We also can't feasibly create tools to patch every limitation, since this would lead to an infinite number of specialised tools for infinitely many edge cases (if we could systematically cover every gap with a tool, we'd have solved AGI by now). Hence, our job is to bring the principles. Judgement calls, novel situations, and knowing which patterns even apply are on us. The model provides the patterns, and we provide the principles.
The illusion of "memory"
Another fact that often surprises people is that there is no actual memory in a conversation with LLMs. Today's LLMs are stateless, which means they don't remember previous conversations, and each message is processed independently without any context from previous sessions.
When you send a message, here's what actually happens:
Your first message:
Input: "What's a good recipe for pasta?"
Output: [recipe]Your second message:
Input: "What's a good recipe for pasta?
[full previous response with recipe]
Can I substitute the tomatoes?"
Output: [substitution suggestions]The entire conversation history from this session is re-sent every single time, and the model re-reads everything from scratch and generates a response.
This works because after training, the model's parameters (those billions of numbers) become completely frozen. Training is expensive, so once it's done, the model gets locked in place. This also ensures consistency, since you don't want random conversations changing how the model behaves. Consequently, the model can't learn from your chats or update its weights, and every user talks to the exact same snapshot.
Think of it like a factory that mass-produces identical robots. To start a conversation, you pull one off the assembly line, it responds, and then shuts down. For your next message, you grab another identical robot and hand it a transcript of everything said so far. It reads the whole thing, responds, and shuts down. None of the robots remember anything; they just read whatever notes you hand them. What makes each conversation different isn't the robot; it's the transcript.
Modern LLM products work around this by offering "memory" features, which summarise past conversations and slip that summary into the beginning of new chats. It's like stapling a "previously on..." summary to the front of your transcript every time. While this isn't true memory, it does create the illusion of continuity.
Why context has limits
Context windows exist because longer conversations require exponentially more computation costs, and every token you add increases the work the model has to do. Consequently, there's a maximum cap on context length, which varies depending on the model. For example, Sonnet 4.5 and Opus 4.5 from Anthropic have a context window of 200K tokens, OpenAI's GPT-5.2 has 400K tokens, and Google's Gemini 3 has 1M tokens.
However, even with conversations fitting inside the token limit, quality degrades as the conversation grows. This is sometimes called context rot, where the model's attention gets diluted and details get lost, especially information buried in the middle. Models typically attend more strongly to the beginning and end of the context.
Consequently, token efficiency isn't just about fitting within the limit; it's also about keeping the signal-to-noise ratio high. A leaner context means better attention on what matters.
In addition, once a conversation goes down the wrong track, it's very difficult to undo. That wrong direction is now part of the transcript that the model re-reads every time, and although you can try to correct course, earlier missteps will still influence the output. Sometimes the best move is to start fresh rather than fight a polluted conversation.
For important tasks, this means: keep things focused, put critical information at the start or end, and don't be afraid to start fresh when a conversation gets unwieldy.
Putting it all together
Before LLMs, most of us had a backlog of ideas we'd never get to, whether side projects, tools, or experiments we couldn't justify the time for. Time was the bottleneck, not imagination. That equation has now shifted, since the new bottleneck isn't time but rather knowing how to use these tools.
Think of an LLM as a tireless assistant who can draft, research, and build, but needs you to steer. You bring judgement and context; they bring speed and pattern-matching. When this works well, it's surprisingly productive. Problems occur when the balance breaks down, like when you expect principles from a pattern-matcher, or when context gets lost in the noise.
Common problems and how to fix them
"It states things confidently that are wrong"
This is the most common frustration. The model delivers an answer with complete confidence, and it's just... wrong. This happens because LLMs learned patterns, not principles: they know what correct answers look like, but not how to verify truth. In addition, since their training data is frozen at a cutoff date, anything recent is simply invisible to them.
Fix: Treat specific claims (names, dates, URLs, statistics, and citations) as "plausible but unverified". If it matters, verify it. For current information, explicitly ask the model to "search the web for" or "look up" a topic, since most modern LLMs today have web search built in via tool calling. You can also paste URLs directly into the chat to give the model authoritative source material to work from. Ultimately, LLMs are excellent at synthesis and explanation, but they're unreliable as a source of record.
"My conversation got worse over time"
You started with great results, but twenty messages later, the model seems confused, forgetting details you mentioned and drifting from your original intent. This isn't your imagination. Recall that LLMs are stateless, and every response requires re-reading the entire conversation transcript. As that transcript grows, attention gets diluted, information buried in the middle gets lost, and any wrong turns become part of the context that the model keeps re-reading.
Fix: Keep conversations focused. Periodically restate critical requirements and goals, and put them at the beginning or end of your message where attention is strongest. When a conversation has gone off track, recognise when to start fresh rather than fight a polluted transcript. Sometimes the best prompt is a blank slate.
"It just agrees with everything"
Ask Isn't X the best approach? and the model might respond with Yes, you're right!. This sycophancy happens because LLMs were fine-tuned on countless helpful Q&A conversations as training data, where "helpful" looked like agreeing and validating. The model pattern-matches that perfectly, which ironically backfires when you need honest pushback.
Fix: Frame questions neutrally by asking What are the tradeoffs of X? instead of Isn't X great?. You can also explicitly request critical analysis by asking What would someone who disagrees with this approach say?. Effectively, give the model permission to push back.
Prompting patterns that work
Models try to predict what should come next, so your job is to make the "right" response the most probable one.
- Be specific. Vague prompts have many plausible completions, whereas specific prompts narrow down what "good" looks like.
- Provide context. Include what the model can't know, like your situation, your constraints, and what you've already tried.
- Show examples. Leverage the model's pattern-matching strength: if you want a specific format or style, demonstrate it.
- Adjust temperature. If you need consistency, lower the temperature; if you want creative exploration, raise it. Effectively, it's a dial between reliability and surprise.
- It's worth noting that most consumer chat interfaces (ChatGPT, Claude, Gemini) don't expose this setting directly, since it's typically an API-only feature. However, you can influence the output style through prompting, like by assigning a creative role, asking for multiple variations, or specifying the tone you want. Just saying "be more creative" is too vague to be effective.
In Practice:
A recruiter writing outreach shouldn't ask Write an outreach message for a software engineering candidate.. Instead, they should specify: Write a LinkedIn outreach message for a senior backend engineer. We're a Series A fintech company, 10 people, building payment infrastructure. Candidate has 6 years at Amazon. Warm but not salesy, under 100 words.
Likewise, a PM drafting requirements shouldn't ask Help me write a PRD for SSO login.. Instead, they should provide: Draft a PRD for adding SSO to our B2B SaaS. 50 enterprise customers requesting it, current auth is email/password. Include user stories and acceptance criteria. Skip implementation details.
The pattern here is to narrow the space of possible responses until the right answer is obvious.
Regarding information density in prompting, don't stress too much about being super concise and maximising token efficiency. In the grand scheme of things, the focus should be on including the right information rather than on optimising your prompt to reduce token usage.
Where LLMs excel (and where they don't)
So what should you actually use LLMs for, and can they think "outside the box"?
Exploratory Creativity? Yes.
LLMs are great at conceptual blending: connecting dots across fields, finding patterns in large amounts of information, and generating variations on themes. They can help you brainstorm angles you wouldn't have considered, synthesise research across domains, and explore a problem space quickly.
They also do this fast, which is the real advantage. Tasks that would take hours or days of research and drafting can now happen in minutes, which means more of your ideas actually get explored.
However, all of this creativity happens within the box of existing knowledge. The model recombines patterns it's seen; it's interpolation, not extrapolation.
Transformational Creativity? No.
LLMs can't make paradigm-breaking leaps, invent concepts with no statistical precedent, or reason their way to conclusions that contradict the patterns in their training data.
Consider the following thought experiment: imagine an LLM trained only on knowledge from 1000 AD. It would confidently recommend bloodletting to cure ailments, insist that Earth is the centre of the universe, and have no path to germ theory or Einstein's theory of relativity. It can only recombine what it's seen; it can't make the leap that says "everything we thought was wrong".
Today's models have the same limitation. While they're very good at working within known paradigms, they can't transcend them.
When to skip the AI
Not everything benefits from AI assistance:
- Anything requiring context the model can't access. Team dynamics, company politics, why a project failed last year, internal docs, and decisions that were never written down all fall into this category. Even with web search, if the answer lives in someone's head or behind a login, AI can't help. It can help you think through options, but the judgement is yours.
- High-stakes content you won't review. AI can draft, but if it's going to a customer or executive, you need to read every word. The 5% that's wrong could be the part that matters most.
- Tasks where "mostly right" is worse than "obviously wrong". A legal clause that's 90% correct can be more dangerous than a blank page.
The bottom line
LLMs are prediction engines that learned patterns from text: what good answers look like, how conversations flow, and what helpful responses sound like. They're powerful because those patterns cover a lot of ground, but they're also limited because patterns aren't principles.
When things go wrong (hallucinations, context degradation, sycophancy), it's not random; it's the mechanism showing through. Naturally, knowing the mechanism means you can work around it by verifying claims, keeping conversations focused, asking neutral questions, and starting fresh when needed.
These tools won't replace your judgement, but they can multiply what you're able to research, draft, and explore. That side project you never had time for? You might actually build it now.
Ultimately, this is also why today's AI isn't replacing humans anytime soon. Pattern-matching at scale is useful, but principles, context, and judgement still come from you. The model predicts what a good answer looks like, and you decide whether it actually is one.
P.S. - What about AGI?
This concludes the practical guide, but if you're curious about the philosophy and future of AI, keep reading.
Today's LLMs learn from discrete snapshots of static text, images, audio, and video. They're trained once, frozen, and subsequently served to millions unchanged.
However, what if that changes? There's active work on continuous learning systems, AI agents that learn from consequences, and simulations that provide embodied interaction. The gap between "observing artifacts" and "experiencing reality" might consequently narrow over time.
Nobody knows what's required for general intelligence: maybe it's scale, maybe it's continuous feedback, or maybe something we haven't thought of yet.
The honest answer is that we're building systems we don't fully understand, hoping to reach a destination we can't clearly define. That's either the most human thing imaginable, or a recipe for surprise.
Either way, today's AI tools are already powerful enough to change how we work, and we should learn to use them well.